Stochastic Neighbor Embedding非线性降维简介
概述
SNE是一种非线性数据降维方法,对高维数据降维到2维或者3维有助于将数据用图像的方式展示出来. 在以前,说到数据降维,我一般直接的考虑就是PCA(主成分分析), PCA是高维数据到低维数据的线性映射, 还有一些方法如LLE(Locally Linear Embedding).
下面是在scikit-learn上面的一个比较各种方法的例子
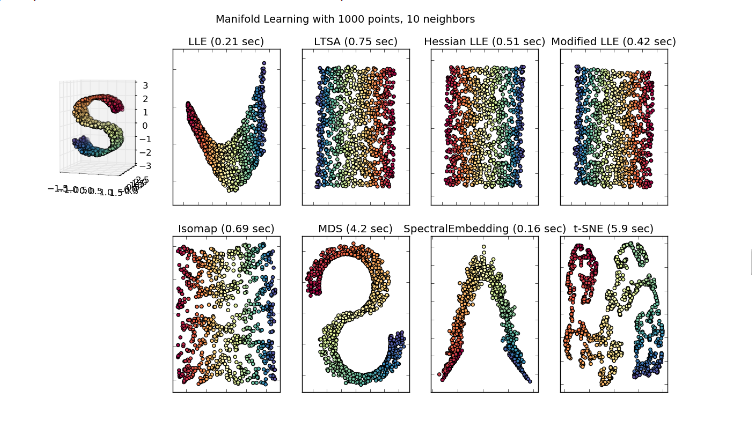
可以看出在上面这个3维转2维的过程中
- SNE算法降维后点分布呈现离散化和团簇化, 备注,实际上SNE的效果不是那么的好,t-sne在全局各族之间分离上做的好一些
- SNE算法追求相对性,而非一个绝对的映射和变换,这里相对性指在高维空间相似的点在低维空间也相似,而不相似的点在低维空间也不相似
基本算法
SNE算法是基于概率框架的算法,简单归纳为, 在高维空间点与点相邻(相似)的概率分布和降维后在低维空间相邻(相似)的概率分布尽可能一致. 所以要做的基本任务有3件
- 高维空间的点与点相邻的概率分布p
- 低维空间的点与点相邻的概率分布q
- 让q的分布尽可能与p的分布一致
关于高维空间的点与点相邻的概率分布p
在2002年的paper定义为
其中d的定义为点i与点j在高维空间的不相似度, 一个具体的方法是用缩放过的欧氏距离平方,注意根据具体的应用应该使用合适的定义而非一定是欧氏距离
而$\sigma$的选择方法为
- 在2002年的paper提到可以作为超参对于某些应用进行手工选择
- 在2002年的paper和后续的t-SNE算法中是以$x_i$为中心做高斯分布该高斯分布能’有效覆盖相邻点的数量为K’,或者说该分布的复杂度(perplexity)为K.而K是一个超参. 直观的讲,如果点$x_i$处于数据稠密区域, $\sigma$就应当小. 如果$x_i$处于数据稀疏区域,$\sigma$就应该大, 大的$\sigma$导致高斯分布扁平化’有效’覆盖的区域也就越大.
关于复杂度perplexity的理解
- 离散概率分布的复杂度定义为$2^{H(p)}$, 如果p为K个选择的均匀分布则其熵$H(p)$为$-\sum_xp(x)log_2p(x)$, 复杂度perplexity为K
- 再举个Wiki上的例子如果一个离散的2选1,如果概率分布为均匀分布即(0.5,0.5)那么复杂度为2, 如果概率分布为(0.9,0.1), 则根据定义复杂度perplexity为
下面是wiki上高斯分布的截图.
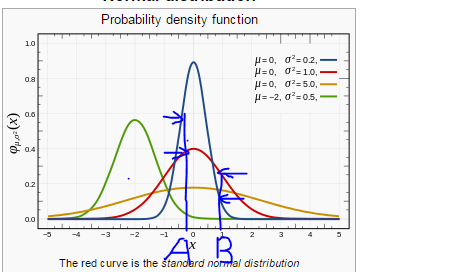
- 可以看出但$\sigma$增大时,相对较远一点的点如B点作为相邻点的概率会增大,而即使非常相邻的点如A点其概率反而会变小一些,这样复杂度perplexity会变大,反之如果固定复杂度,则高斯分布的中心点如果处于数据密集区则相应要调小$\sigma$
低维空间的点与点相邻的概率分布q
上面的式子也是高斯核,不过其方差variance也就是$\sigma^2$被固定为$1/2$,$y_i$和$y_j$为相对应低维空间的点
让q的分布尽可能与p的分布一致
采用梯度下降法,需要给出代价函数(cost function)和关于$y_i$的一阶偏导.
梯度下降法是机器学习的最基本方法,请参见维基百科.
代价函数需要能够衡量低维空间的分布与高维空间的差距. 常见的函数就是KL散度(Kullback-Leibler divergences),也叫相对熵. 具体公式如下
具体含义请参见维基百科
代价函数关于$y_i$的一阶偏导为
注意代价函数是非凸函数non-convex,所以在最速下降法时会陷入局部最优点而非全局最优. 2002年的paper中采用额外加入一个随机量该随机量随时间而慢慢减小,思路上就像模拟退火的思路.
关于低维空间上相应点的起始位置为随机的位置,这些随机的位置很接近原来的位置.
这里原来的位置可以是高维空间点的位置在低维空间的线性映射的位置, 实际的一种做法可以是使用PCA做线性的降维来得到(我觉得其实完全随机的位置也是可以的,不过训练时间会很长). 设定起始位置之后用梯度下降来调整$y_i$是代价函数最小化
注: 在后来的t-SNE用PCA做线性降维只是减少运算量,例如将784维降维到30, 低维空间的起始点就是随机的
其他
关于paper中提到的混合版本,对复杂度进行退火等问题这里就不研究了,毕竟现在大家常用的是SNE算法的变种t-SNE.
总结
该方法思路清晰,目标明确(在高维空间上相邻/相似的点在低维上也相邻,在高维空间上相隔远的点在低维上也相隔远). 实际效果上不仅降维,同时在低维空间上也能聚类.
因为对高斯核, KL散度都学习过,本来以为很快就能搞懂,实际上数学功底还是不行,在$\sigma$的选择上花了半天时间才搞明白.
运行代码来实际检验的步骤就略去. 毕竟回头还要再说一下t-SNE,在t-SNE的介绍中再用代码来实践.
参考
http://www.cs.toronto.edu/~fritz/absps/sne.pdf Geoffrey Hinton, Sam Roweis